Agentic AI Testing for Software Test Engineers

Software testing is changing faster than ever. For years, QA automation engineers relied on Selenium scripts, XPath locators, and brittle CI pipelines. Modern applications are increasingly too dynamic for traditional automation alone.
AI-generated UIs, rapidly changing front ends, microservices, and continuous deployment make script-heavy testing difficult to maintain at scale. Agentic AI testing is one response: autonomous agents that interpret goals, choose actions, and adapt when the product changes.
What is agentic AI testing?
Agentic AI testing means using autonomous AI agents that can:
- Understand testing goals
- Plan workflows
- Execute browser or API actions
- Analyze failures
- Adapt to UI changes
- Self-heal broken tests
- Generate new edge cases dynamically
Unlike traditional automation, where engineers define every step, agents often work from intent.
Traditional automation might look like this:
await page.click("#login-btn");Agentic testing might be expressed as a goal, for example: Validate the login workflow and surface edge-case failures.
The model still needs guardrails (deterministic checks, reviews, and telemetry), but the shift is real: engineers define what to achieve; the agent proposes how, within constraints you set.
Why traditional automation struggles
Classic frameworks assumed relatively stable UIs. Many systems today are not stable in that sense: components churn, selectors drift, async rendering causes flakes, and some experiences are partly machine-generated.
Teams often spend disproportionate time maintaining automation instead of growing coverage.
| Problem | Impact |
|---|---|
| Broken selectors | Constant maintenance |
| Flaky tests | Unstable pipelines |
| Limited coverage | Hidden production bugs |
| Slow test creation | Delayed releases |
| Hardcoded assertions | Low adaptability |
Agentic approaches do not remove engineering judgment, but they can reduce purely mechanical rework when the UI moves—especially when paired with memory, observability, and validation patterns below.
Core architecture of agentic testing systems
Most serious agentic testing stacks combine several layers: reasoning, orchestration, execution, memory, and observability. The diagram below summarizes a typical five-layer pattern and how it connects to applications under test.
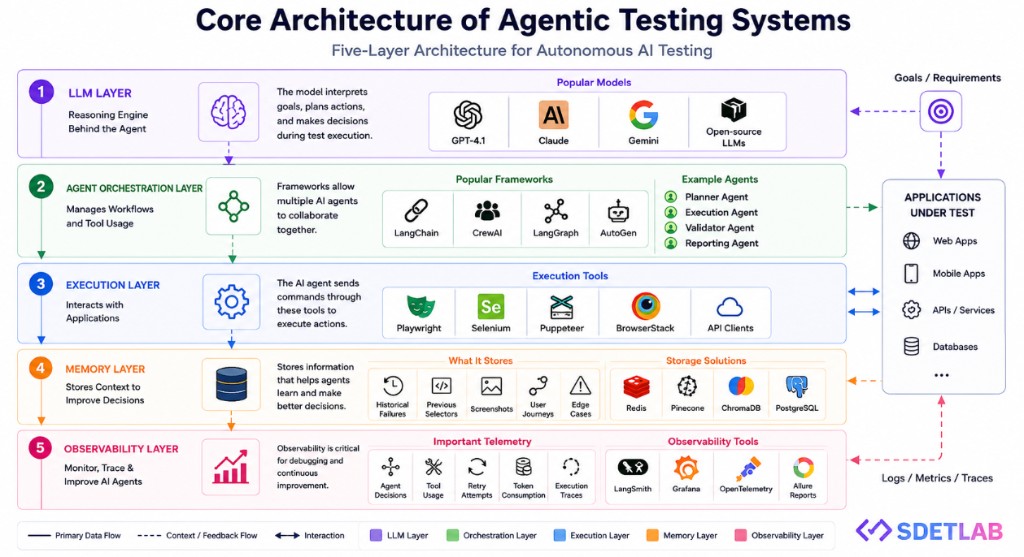
1. LLM layer
The reasoning engine behind the agent. Popular families include GPT-4.1, Claude, Gemini, and capable open-source models. The model interprets goals, plans actions, and makes decisions during a run—always subject to your policies and validators.
2. Agent orchestration layer
Manages workflows and tool use. Common frameworks include LangChain, CrewAI, LangGraph, and AutoGen. Many teams split responsibilities, for example:
- Planner agent
- Execution agent
- Validator agent
- Reporting agent
3. Execution layer
Talks to the real system under test—often via Playwright, Selenium, Puppeteer, cloud grids such as BrowserStack, or API clients. The agent issues actions; the tools enforce browser or protocol reality.
4. Memory layer
Agents benefit from retained context: historical failures, prior selectors, screenshots, user journeys, and edge cases. Storage might include Redis, Pinecone, ChromaDB, PostgreSQL, or similar, depending on whether you need vectors, structured rows, or fast cache semantics.
5. Observability layer
Telemetry is non-negotiable for AI systems in CI: agent decisions, tool calls, retries, token usage, and execution traces. Teams often wire in LangSmith, Grafana, OpenTelemetry, Allure, or equivalent so failures are explainable and comparable across runs.
Traditional testing vs agentic testing
| Traditional testing | Agentic AI testing |
|---|---|
| Script-based | Goal-based |
| Static locators | Adaptive locators (with validation) |
| Manual debugging | Reasoning plus traces |
| Reactive maintenance | Self-healing where safe |
| Limited edge exploration | Directed exploration |
| Human-only execution | Autonomous execution (supervised) |
How AI testing agents typically work
A common reasoning loop looks like this:
- Understand the goal — e.g. validate checkout for guest users under load.
- Create an execution plan — decompose into navigable steps (home → cart → shipping → payment → confirmation).
- Execute actions — drive Playwright or APIs with tools the orchestrator exposes.
- Analyze results — assertions, responses, console noise, visual diffs where used.
- Retry or heal — distinguish timing issues, selector drift, environment problems, and true defects; escalate or repair per policy.
That loop is what makes automation feel adaptive compared to a single linear script.
Self-healing automation
Self-healing is a headline feature: when #login-button becomes #submit-login, a brittle script fails immediately. A well-designed agent can re-ground in the DOM (labels, structure, accessibility, nearby text, history of working locators) and continue—if you validate the new target (never trust the model alone for safety-critical actions).
Agents often combine:
- DOM structure and roles
- Neighboring elements and visible text
- Historical selectors from memory
- Accessibility names
- Optional visual similarity
Reported outcomes vary by team, but directions are consistent: fewer flakes from minor UI churn and less manual locator firefighting, provided observability proves what actually ran.
Hallucination risk in AI testing
Agents can misread state: assume an element exists, invent assertions, or overfit a narrative to logs. In pipelines, that is dangerous.
Mitigations that matter:
- Deterministic validation — ground truth from DOM, network, and application state; treat the LLM as a planner, not the sole oracle.
- Multi-agent checks — one agent acts; another independently verifies critical steps or outputs.
- Confidence thresholds — block or escalate low-confidence actions.
- Screenshot or visual regression tools — e.g. Applitools, Percy, or similar, where visual contracts matter.
Skills SDETs are leaning on in 2026
- Playwright (and solid browser fundamentals)
- Agent frameworks — LangChain, CrewAI, LangGraph patterns
- Prompt and policy design — constraints, tools, and refusal behavior
- Observability — logs, traces, metrics, cost dashboards
- Python — still the default glue for many AI and tooling ecosystems
Where agentic QA is heading
Expect more autonomous regression, richer pipeline telemetry, AI-assisted environments, and stronger validation layers—not “unattended magic,” but goal-driven automation with explicit safety properties.
The arc many teams describe:
Goal → AI planning → AI execution → AI validation → AI reporting…with humans owning risk, data, and release decisions.
Why this matters now
Strong product companies already ask engineers to design AI-aware quality systems: self-healing strategies, exploratory agents, flaky detection, and observable automation. Combining Playwright-class execution, agent orchestration, and telemetry is quickly becoming a high-leverage SDET skill set.
Final thoughts
Agentic AI testing is not a passing buzzword; it is part of the next wave of software quality engineering. Teams that adopt it thoughtfully—clear goals, deterministic checks, memory, and observability—can ship faster with more maintainable automation and clearer evidence when something breaks.
The SDET role keeps expanding: not only “test automator,” but systems thinker across agents, tools, and production feedback. Starting now puts you ahead of teams still treating every release as a fresh battle with selectors alone.