Modern Test Pyramid 2026: Complete Strategy
Mike Cohn’s test pyramid (from Succeeding with Agile, 2009) still names something true: fast, cheap checks at the bottom; slower, broader checks toward the top. What changed is everything around it—microservices, serverless, mobile networks, AI features, and edge deployments—so the shape of a healthy portfolio in 2026 is often wider in the middle, thinner at the UI tip, and wrapped in observability that behaves like continuous testing in production.
This guide gives you a complete strategy: how to think about each layer, which tool categories map where (including platforms such as Sauce Labs and BrowserStack for grids and device coverage), how to phase adoption without boiling the ocean, and which metrics keep leadership aligned.
For E2E stack choices, pair this with Playwright vs Selenium vs Cypress: 2026 Comparison; for flaky-suite triage, see Fix Flaky Tests: 2026 Masterclass and No-BS Playbook: Fix Flaky Tests Without Slowing Releases.
Why the classic pyramid strains in 2026
Monolith-friendly pyramids assumed most behavior lived behind one deployable and that UI tests were the main “integration reality check.” Today:
- Microservices push failures to wiring—schemas, auth, versioning, retries—not single-process unit edges.
- Serverless and edge add cold starts, regional variance, and quotas; mocking “the whole world” stops paying off quickly.
- Mobile and rich web (React Native, Next.js, streaming clients) multiply state, hydration, and network sensitivity—classic UI-heavy suites become flaky and expensive without a strong API and contract spine.
- AI/ML features need data and behavior drift signals, not only green unit tests on deterministic code paths.
Industry surveys from test automation vendors—for example resources published by Sauce Labs and Tricentis Testim—routinely report large fractions of engineering time going to test maintenance and pipeline instability. Treat those figures as directional: your own audit (runtime, flake rate, escaped defects) should drive investment, not a headline percentage alone.
Modern pattern: treat API and contract tests as the primary regression net, keep unit tests lean and meaningful, cap UI/E2E to high-value journeys, and let synthetics + SRE telemetry catch what automation never will.
The 2026 model: layers plus an observability halo
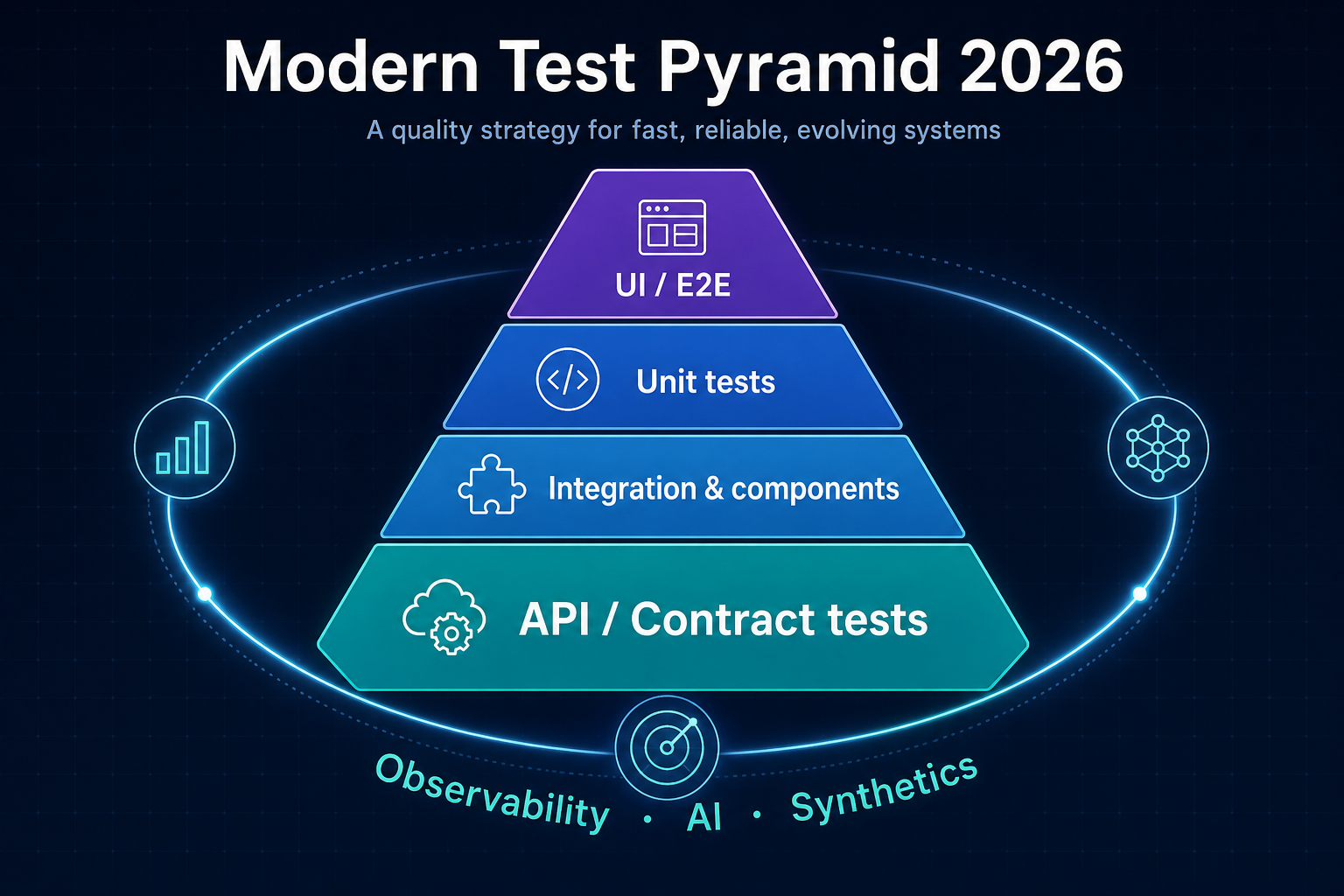
Think hexagonal stack + orbit:
- Unit — fast feedback on pure logic (still essential, not necessarily “most tests by count” if APIs carry weight).
- API / contract — largest share of defect prevention per minute for distributed systems.
- Integration / component — real databases, queues, and HTTP edges in controlled environments (Testcontainers is the common default for JVM and polyglot stacks).
- UI / E2E — few journeys, maximum signal; often run on cloud device and browser grids (BrowserStack, Sauce Labs) when you need real devices, locales, or carrier-adjacent behavior.
- Halo: observability, synthetics, chaos, AI monitoring — not “above UI”; around the pyramid—Datadog, New Relic, Checkly, Gremlin, and ML observability tooling sit here.
Below, each layer includes goals, tools with outbound links (useful for readers and for future affiliate or partner programs—you can later swap these for tracked or partner URLs without changing the article structure), and implementation notes grounded in SDET practice (including Appium/TestNG-style backends).
Layer 1: Unit tests — lean, precise, property-aware (roughly 20–30% of meaningful assertions)
Goal: Prove business rules and invariants quickly—sub-second per module where possible—not wallpaper coverage with brittle mocks.
Principles
- Prefer fewer, stronger tests over one-test-per-line coverage theater.
- Add property-based and generative cases where inputs are huge: jqwik on the JVM, Hypothesis in Python, fast-check in TypeScript—complement example-based tests, not replace critical examples.
- Use mutation testing (Stryker for JS/TS, PIT for Java) to ask whether your tests actually disprove broken code.
- AI assistants (e.g. GitHub Copilot) can draft tests and properties; humans still own oracle design and risk prioritization.
Example (JVM, TestNG-style + AssertJ) — traditional example-based:
@Test
void fareScalesWithDistance() {
var calc = new RideCalculator();
assertThat(calc.fare(5.0)).isEqualTo(25.0);
}Example (property-shaped check with jqwik) — sketch of the idea; wire your own calculator rules:
import net.jqwik.api.*;
class FareProperties {
@Property
void fareIsNonNegativeForPositiveDistance(@ForAll @Positive double distance) {
var calc = new RideCalculator();
assertThat(calc.fare(distance)).isGreaterThanOrEqualTo(0.0);
}
}Mobile twist: keep heavy logic out of the UI layer—test RN/Flutter pure modules with Jest/Dart tests; push pricing, eligibility, and entitlements to API-testable services.
Metrics: median test time per package, mutation score where enabled, JaCoCo or native coverage only as a guardrail, not the goal.
Layer 2: API and contract tests — the dominant base (often 50–60% of automated value)
Goal: Lock producer–consumer contracts and API behavior (REST, GraphQL, gRPC) faster and more stably than UI replay.
Why this layer wins
- Parallelizes cheaply compared to full browser runs.
- Maps cleanly to microservice boundaries and serverless handlers.
- Supports consumer-driven contracts with Pact or Spring Cloud Contract so teams ship independently without silent breakage.
- Stubs and virtual services (WireMock, mock servers) keep CI deterministic while still exercising real HTTP stacks.
Tooling map (with outbound links)
| Need | Example platforms / tools | Typical use |
|---|---|---|
| Contract tests | Pact | CI verifies consumer expectations against provider contracts |
| HTTP scenarios | REST Assured, Karate | JSON/XML assertions, parallel CI slices |
| Design + CI collections | Postman + Newman | Shareable collections, Newman in pipelines |
| Schema / GraphQL governance | GraphQL Inspector | Breaking-change detection on schema rollouts |
| AI-assisted exploration | Vendors such as Tricentis Testim | Flake analytics, stabilizers—evaluate against your stack |
Resilience testing: inject latency and faults with Toxiproxy or similar so “works on my fiber” does not equal “works in EU mobile conditions.”
Concrete habit: for every new service endpoint, add contract + negative tests (auth, validation, rate limits) before you add a second UI test that clicks the same path.
Layer 3: Integration and component tests — service reality (roughly 15–20%)
Goal: Prove adapters against real-ish infrastructure: Postgres, Redis, Kafka, object storage—without full production.
Patterns
- Testcontainers for ephemeral databases and brokers; keep tests parallel-safe with unique DB names or schemas per worker.
- Hexagonal / ports-and-adapters: tests target ports (interfaces) with real or containerized adapters, not mocks of your own domain.
- Record-replay tools such as Keploy can capture traffic-shaped tests—treat as accelerator, not a substitute for contracts.
Example skeleton (TestNG + Testcontainers, Java)
@Testcontainers
class RidePersistenceIT {
@Container
static PostgreSQLContainer<?> postgres = new PostgreSQLContainer<>("postgres:16");
@Test
void persistsRide() {
// wire DataSource to postgres.getJdbcUrl(), run service, assert row state
}
}Metrics: p95 test duration per integration module, failure correlation with infra (disk, pool exhaustion).
Layer 4: UI and E2E — synthetic journeys and visuals (cap near 5–10% of suite cost, not ambition)
Goal: Protect revenue and trust paths (signup, pay, ship, stream) with minimal browser automation.
Tactics
- Playwright or Cypress for web; Appium for native/hybrid mobile—see the framework comparison.
- Visual regression: Applitools or Percy (Percy sits under the BrowserStack portfolio) for component and page baselines—great for design-system drift.
- Real device / browser coverage: run a small nightly or pre-release matrix on BrowserStack or Sauce Labs for OS versions, RTL, and low-bandwidth profiles you cannot model locally.
- Cap journey count per app surface; push everything else to API + component tests.
Example (Appium + visual check conceptually)
@Test
void criticalCheckoutJourney() {
driver.findElement(By.id("add-to-cart")).click();
// Applitools Eyes: eyes.checkWindow("Checkout");
}Pair UI tests with strict data setup via APIs so flakiness is not “DB seed race #7.”
Layer 5: Observability halo — synthetics, SLOs, chaos, ML drift
This layer is not “more Selenium.” It is continuous verification of what users experience when code is already shipped.
- Synthetic monitoring: Checkly (Playwright-backed checks), or vendor APM synthetics from Datadog and New Relic.
- Chaos and fault injection: Gremlin or cloud-native game days—validate retries, circuit breakers, and backoff.
- ML / data quality: pipeline tests with Great Expectations, drift monitors, and shadow traffic where policy allows—complement model unit checks in notebooks or TFX-style pipelines.
SRE-aligned KPIs: error budget, burn rate, synthetic success rate, and MTTR—tie quality engineering to customer-visible reliability, not only test pass icons.
AI in the pyramid (without fooling yourself)
Use AI to speed authoring (Copilot, internal LLMs), summarize failures, and suggest locators or API cases—never as the sole oracle on regulated or safety-critical behavior without human review.
Self-healing and AI-assisted runners (commercial offerings from vendors including Tricentis Testim and others) can reduce noise when paired with root-cause ownership; they should not hide systemic coupling or missing contracts.
Building it: phased implementation
Phase 1 — Audit (about a week)
- Inventory tests by layer, owner, median duration, flake rate, and business criticality.
- Map each major user journey to API coverage vs UI-only gaps.
Phase 2 — Refactor the portfolio (weeks 2–4)
- Promote critical UI coverage to API + contract where UI only duplicated HTTP assertions.
- Introduce Pact (or equivalent) on the noisiest service boundaries first.
- Standardize fixtures and parallel isolation (see Fix Flaky Tests: 2026 Masterclass).
Phase 3 — CI/CD wiring (week 5 onward)
- Split jobs by layer: unit, contract/API, integration, E2E, nightly device matrix on BrowserStack or Sauce Labs.
- Example shape (GitHub Actions style—adapt names to Maven/Gradle/npm):
jobs:
tests:
strategy:
matrix:
suite: [unit, contract, integration, e2e-smoke]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run suite
run: echo "mvn -P${{ matrix.suite }} verify # replace with your runner"- Use Vercel (or similar) preview deployments for PR-level smoke against ephemeral environments—keep secrets and data out of public previews.
Phase 4 — Metrics and iteration
| KPI | What “good” tends to look like | Where to measure |
|---|---|---|
| Pipeline wall time | PR signal in single-digit minutes for default path | CI analytics |
| Flake rate | Trending down; top flakes have owners | Reruns + history |
| Escaped defects | Fewer sev-1/2 tied to missing contract or synthetic | Incident retros |
| Cost | Device minutes tracked; grids used intentionally | BrowserStack / Sauce dashboards |
Reporting layers like Allure Report (via Qameta) help communicate trend, not just last run green/red.
Cost and vendor placement
Cloud grids are line items, not shameful secrets:
- BrowserStack and Sauce Labs both offer real device clouds, desktop browsers, and integrations with Selenium, Appium, and Playwright—prices change; use their sites for current plans: BrowserStack pricing, Sauce Labs pricing.
- Visual tools (Applitools, Percy) save rework when UI churn is high—pay for them when design drift is a top defect category.
- Open source first for runners (Playwright, Pact, Testcontainers) keeps you portable; spend vendor budget on what differentiates (devices, visuals, enterprise compliance).
Case pattern: “streaming-style” product (inspired by public architectures)
Teams with high read volume and global CDNs typically:
- Cut UI share of CI time by moving playback, entitlement, and catalog invariants to API + contract suites.
- Run narrow E2E on checkout, auth, and offline/error paths.
- Use synthetics from multiple regions to catch DNS, TLS, and routing issues unit tests will never see.
Your numbers will differ; always record before/after for runtime, flake rate, and escaped bugs.
Challenges and straight answers
| Challenge | Response |
|---|---|
| Flaky E2E | Shrink UI scope; stabilize data; use grids for real devices only where needed—BrowserStack / Sauce Labs |
| “We need AI retries” | Cap retries; fix contracts and waits—see Fix Flaky Tests: 2026 Masterclass |
| Legacy UI-only suites | Strangler: each sprint, move one journey’s assertions to API + one visual baseline |
| Leadership skepticism | Show pipeline minutes, MTTR, and escaped defect deltas tied to layer changes |
Looking toward 2027 (short)
Expect more WASM in clients, stronger supply-chain and crypto agility testing, and tighter coupling between feature flags, synthetics, and release governance. The pyramid is a thinking tool, not a religion—adapt the ratios to your risk and architecture.
Conclusion
The Modern Test Pyramid 2026 is contract- and API-heavy, UI-thin but high value, integration-realistic, and wrapped in observability. Pair open-source runners with intentional spend on grids (Sauce Labs, BrowserStack), visuals (Applitools, Percy), and telemetry (Datadog, New Relic) where they reduce real business risk. Audit, shift mass to APIs, cap UI cost, measure ruthlessly—then your pyramid supports speed and SRE-grade reliability at the same time.