Risk-Based Testing Framework for Enterprise Teams (2026)
Written by Kajal · Reviewed and published by Prasandeep
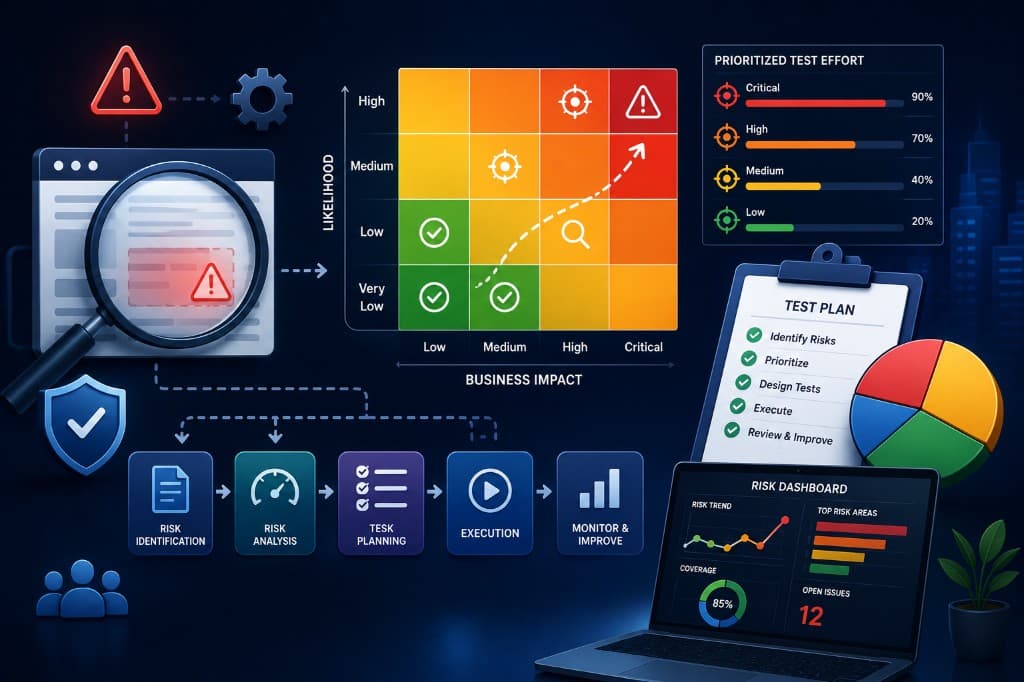
Software delivery cycles are faster than ever. Teams ship weekly—or daily—across microservices, mobile apps, APIs, AI-powered features, and multi-region deployments. At the same time, organizations must manage regulatory obligations, security threats, uptime targets, and customer expectations. Testing budgets, however, rarely grow at the same pace.
Risk-Based Testing (RBT) provides a structured way to allocate limited testing capacity where it delivers the highest risk reduction. Instead of treating every feature equally, RBT quantifies risk, prioritizes test effort, and continuously aligns testing with business and technical realities. The payoff: fewer critical escapes, more predictable releases, and clearer conversations between engineering, product, security, and compliance.
For portfolio balance and layer mix, see Modern Test Pyramid 2026: Complete Strategy. For boundary testing at scale, see Contract Testing for Microservices: The 2026 Definitive Guide. For pipeline selection and ordering, see GitHub Actions + Playwright CI/CD pipeline. For career context on test strategy ownership, see SDET Career Roadmap 2026.
What is risk-based testing?
Risk-based testing is an approach where test planning, design, and execution are driven by an assessment of risk: the combination of how likely something is to go wrong and how bad it would be if it did.
More precisely:
- Risk is the chance of a failure multiplied by the impact of that failure on business, users, or operations.
- A risk-based testing framework is a systematic process that identifies risks, quantifies them, and maps them to concrete test activities and priorities across the lifecycle.
Instead of “run all regression tests before every release,” you move to “invest most effort in high-risk areas, provide adequate coverage for medium risk, and minimal or lightweight checks for low risk.”
For enterprises, that shift matters: teams can justify testing decisions with transparent risk models instead of intuition or habit alone.
Why enterprises need a risk-based testing framework
At enterprise scale, the question is rarely “Do we test?” but “Where do we put the next hour of testing?” Risk-based testing answers that in a repeatable way.
Key drivers:
- Complex portfolios — Multiple products, channels, integrations, and legacy systems make equal testing of every combination impossible.
- Regulation and compliance — Banking, healthcare, insurance, telecom, and public-sector programs must prove that critical and regulated functions receive sufficient, traceable testing.
- Security and privacy — Data-protection laws and threat models make some flows (authentication, payments, PII handling) far more sensitive than others.
- Limited budgets and time — Even large teams face constraints on environments, specialist skills, and release windows.
- Evolving customer expectations — Multi-device and multi-channel journeys increase the surface area where defects damage reputation.
A well-designed framework gives leadership a common language for trade-offs: what risk remains in this release, which areas are under-tested, and where to invest automation next.
Core principles of risk-based testing
Across implementations, a few principles show up consistently:
- Context first — Risks must be defined in relation to organizational goals, domain, architecture, and regulatory constraints. There is no one-size risk model for every product.
- Quantification over intuition — RBT uses structured scoring (likelihood × impact) or more advanced models rather than gut feeling alone.
- Traceability from risk to tests — Every high-risk item should map clearly to test objectives, specific test cases, and exit criteria.
- Dynamic and iterative — Risks change as features evolve, incidents happen, and controls improve. RBT must be updated from production and test feedback.
- Transparency and collaboration — Business stakeholders, architects, security, operations, and QA all contribute to risk identification and scoring.
The enterprise RBT framework: three dimensions
A practical framework can be described in three top-level dimensions:
- Context — Domain and business model; regulatory landscape; architecture and technology stack; organizational risk appetite.
- Risk assessment — Identify risk items (features, flows, components, interfaces); estimate likelihood and impact; calculate exposure and classify levels.
- Risk-based test strategy — Plan objectives and resources by risk level; design and prioritize test cases; execute, monitor, and re-assess during and after runs.
Different teams apply the same logic while tailoring details to their product or domain.
Step 1 — Defining context and risk drivers
A serious implementation starts with context, not scoring.
Key activities:
- Business impact analysis — Identify features that drive revenue, legal obligations, brand reputation, or safety. Examples: payment processing, trading engines, claims handling, clinical decision support, logistics flows.
- Regulatory mapping — Catalogue modules under PCI DSS, HIPAA, GDPR, SOX, PSD2, or industry-specific obligations. These areas usually require stronger evidence of testing and stricter exit criteria.
- Architecture review — Understand microservices, shared platforms, third-party integrations, data flows, and legacy components. High complexity or historical instability typically increases risk.
- Organizational risk appetite — Some organizations tolerate minor UI issues but not security regression; others prioritize operational continuity. This shapes how impact is scored.
You end this step with risk drivers (financial loss, regulatory penalty, data breach, reputation damage, operational disruption) and risk items (features, components, flows) that will be evaluated.
Step 2 — Identifying risks systematically
With context defined, identify specific risks for each module, feature, or user journey.
Sources:
- Requirements and user stories — For each acceptance criterion, ask “What can go wrong here?”
- Architecture diagrams and integration maps — Spot brittle dependencies, single points of failure, complex call chains, and external integrations.
- Past incidents and defect history — Look for recurring issues, fragile components, and areas with high change frequency.
- Stakeholder workshops — Involve business, security, operations, support, and domain experts to capture risks you might otherwise miss.
Typical enterprise examples:
- Payment service fails under concurrent load, causing lost orders.
- Regulatory reporting module produces incorrect data, leading to fines.
- Authentication service outage blocks login across all products.
- Data synchronization issues between mobile and web clients, causing inconsistent states.
The output is a risk register: risk items with descriptions, affected areas, causes, and initial notes.
Step 3 — Assessing and quantifying risk
Risk assessment converts qualitative risks into scores that drive decisions.
A common pattern uses Likelihood (L) and Impact (I) on a 1–5 scale:
- Likelihood: 1 (rare) to 5 (very frequent)
- Impact: 1 (negligible) to 5 (critical)
Then calculate risk exposure as the product of the two scores:
Risk Exposure = L × I
Example: Likelihood 4 × Impact 5 → Exposure 20 (Critical band)
Map exposure into levels, for example:
| Exposure | Level |
|---|---|
| 16–25 | Critical |
| 9–15 | High |
| 4–8 | Medium |
| 1–3 | Low |
More advanced frameworks may:
- Use Risk Priority Numbers (RPN) or similar metrics for finer ranking.
- Add factors like detectability, control strength, or existing test coverage.
- Incorporate historical defect data and production incident frequency to calibrate likelihood.
The goal is consistent, transparent scoring across teams and releases—not perfect mathematics.
Step 4 — Mapping risk to test strategy
This step turns scoring into action. Each risk level maps to test types, depth, and investment.
| Risk level | Typical components | Test focus | Depth and types |
|---|---|---|---|
| Critical | Payments, authentication, safety, regulated flows | Prevent catastrophic failures | Extensive functional, negative, performance, security, exploratory; high automation |
| High | Core business logic, data processing, integrations | Avoid major outages and data issues | Thorough functional and negative, targeted performance and security, solid automation |
| Medium | Standard features, supporting flows | Ensure main scenarios work | Main-path functional, some negative checks, regression automation where cost-effective |
| Low | Cosmetic UI, rarely used tools | Avoid obvious defects | Smoke, happy-path, unit tests primarily |
For each level, define:
- Test objectives — What must be demonstrated? (e.g. no data loss in transfer, access control enforced, throughput meets SLA).
- Techniques — Equivalence partitioning, boundary value analysis, decision tables, state transitions, security and performance tests, exploratory sessions.
- Automation strategy — Which scenarios must be automated at unit, API, UI, or contract level; which remain manual.
- Exit criteria — Defect thresholds, coverage expectations, suites that must be green per risk level.
This mapping becomes a reusable template for all teams. Where microservices dominate, pair critical integration paths with contract tests instead of relying only on heavy end-to-end suites.
Step 5 — Prioritizing test design and execution
With risks scored and mapped, prioritize design and execution.
Practical guidance:
- Design tests from risks, not only requirements — For a high-risk payment flow, cover invalid data, timeouts, third-party failure, concurrency, and security threats.
- Order your backlog by risk — Run high-risk scenarios early in CI and pre-release; medium and low-risk suites can run less often or in later stages.
- Allocate scarce skills where they matter — Performance engineers, security specialists, and domain experts focus on critical and high-risk areas.
- Tie automation priorities to risk — Critical paths get robust automated coverage including negatives; low-risk areas may rely more on unit tests and occasional manual checks.
Tag test cases and suites with risk levels in your tooling so pipelines can select and order them. For flaky high-risk suites, see Fix Flaky Tests: 2026 Masterclass before weakening exit criteria.
Step 6 — Monitoring, reporting, and re-assessing risk
Risk-based testing is continuous. Risk changes as code, infrastructure, and usage evolve.
Good practices:
- Risk dashboards — Visualize risk levels, associated test coverage, open defects, and residual risk per module; track trends.
- Risk-triggered exit criteria — Example: no open critical defects in critical-risk modules; all high-risk scenarios passed in the last N builds.
- Feedback from production — Incidents, near-misses, monitoring alerts, and user feedback adjust likelihood scores and risk levels.
- Calibration workshops — Quarterly or per major release, review scoring, update assumptions, and refine mappings.
This feedback loop keeps the framework aligned with behavior in the field.
Qualitative vs quantitative RBT
Organizations typically adopt one style—or blend them:
- Qualitative RBT — Uses High/Medium/Low classifications and expert judgment; fast to roll out; works when historical data is limited.
- Quantitative RBT — Uses explicit formulas and numeric scores, often incorporating defect rates, change frequency, and operational metrics; may use fuzzy logic or ML to reduce subjectivity where data and tooling are mature.
Many teams start qualitatively and shift toward quantitative models as they gather experience and data.
Integrating RBT with Agile and DevOps
Risk-based testing fits agile and DevOps when framed as continuous risk management, not a heavyweight upfront document.
Patterns that work:
- Risk tags in user stories — Product owners assign preliminary risk during refinement; refine as details emerge.
- Risk-aware Definition of Done — Stories touching high-risk modules require additional test types (performance probes, security checks, chaos experiments) before done.
- Risk-based test selection in CI/CD — High-risk suites on every commit or nightly; medium and low-risk suites less frequently or on specific branches.
- Shift-left and shift-right — Risk assessment informs unit tests, contract tests, and test data (shift-left) and monitoring, alerting, and chaos testing (shift-right).
For AI-assisted generation, keep humans on the critical path for high-risk journeys—see AI Test Hallucinations: Detection and Fixes.
Governance, compliance, and auditability
For regulated domains and larger enterprises, governance is a major benefit of structured RBT.
Benefits:
- Traceable rationale — Show how each major function’s risk level was determined and which test activities followed.
- Evidence for auditors and regulators — Risk registers, matrices, test mappings, and execution reports demonstrate proportionate testing.
- Policy enforcement — Standards like “all PCI-relevant flows are critical risk and must pass specific suites before release” can be codified in pipelines.
- Consistent approvals — When everything cannot be tested, RBT documents residual risk for release and change approvals.
This strengthens trust between engineering, risk management, and leadership.
Common pitfalls and how to avoid them
| Pitfall | What goes wrong | Mitigation |
|---|---|---|
| One-off risk workshops | Models go stale quickly | Embed risk review in planning and release ceremonies |
| Overly complex scoring | Hard to explain and maintain | Start simple; evolve only when necessary |
| Ignoring production data | Speculation misses real patterns | Feed incidents, monitoring, and defect metrics into updates |
| Using RBT to justify under-testing | “Low risk” becomes “no tests” | Set minimum baselines per level and track them |
| No stakeholder involvement | QA-only scoring lacks buy-in | Include product, architecture, security, operations, support |
Tooling and framework patterns
Different organizations combine:
- Risk matrices and visual tools — Collaborative scoring and risk-vs-coverage views.
- Test management platforms — Tag cases and suites with risk levels; select or prioritize in CI.
- Security-focused RBT layers — Threat modeling, vulnerability scanning, and security suites in the same risk model.
- Expert systems for scoring — Rules or fuzzy logic for consistent assignment across teams.
The key is workflow support: capture risk, link to tests, feed execution data back into the model—not a specific vendor logo.
Implementation roadmap for enterprises
A realistic rollout:
- Pilot — One or two products; define context, drivers, and a simple scale; build a matrix and map to test activities; run for a couple of releases and capture feedback.
- Standardization — Extract patterns into a meta-model; document guidelines, examples, and templates; train QA leads, product owners, and architects.
- Tool integration — Risk attributes on work items and test cases; pipelines use tags for selection and ordering.
- Expansion and governance — Roll out to more products; periodic review routines; minimum expectations for high-risk and regulated areas.
- Optimization — Production data, defect metrics, coverage statistics; advanced quantitative models only where they add value.
Incremental adoption reduces friction and improves real adoption rates.
Conclusion
For enterprise teams, risk-based testing is a decision framework that links quality assurance to business risk, regulatory obligations, and operational resilience. By quantifying risk, mapping it to test strategy, and revisiting assumptions over time, organizations focus testing where it delivers the most value—without pretending every area deserves the same depth.
Implemented with collaboration, clear scoring, and strong ties to agile and DevOps practices, an RBT framework aligns product, engineering, security, compliance, and operations on where risk lies and how testing mitigates it. In an environment of fixed budgets and rising complexity, that shared view is a durable advantage.