Self-Healing Tests with AI: Playwright Tutorial (2026)
Written by Kajal · Reviewed and published by Prasandeep

Modern UI tests often break for reasons that have nothing to do with real product bugs. A button label changes, a CSS class is renamed, or a component is refactored, and a previously stable Playwright test fails. The flow still works for users, but your pipeline is red and the team spends time fixing selectors instead of finding defects.
Self-healing testing addresses that by detecting locator drift and attempting recovery instead of failing immediately on the first mismatch. This tutorial explains how to think about AI-assisted self-healing in Playwright, how a production-shaped architecture fits together, and how to keep the system safe, observable, and reviewable. The goal is less locator churn without trading away trust in your suite.
For baseline locator discipline and page structure, see Page Object Model 2026: Best Practices. For flakiness and debugging, see Playwright Flaky Test Debugging in VS Code and Fix Flaky Tests: 2026 Masterclass. For CI wiring, see GitHub Actions + Playwright CI/CD pipeline. For the broader AI-testing landscape, see Agentic AI Testing for Software Test Engineers and AI Test Hallucinations: Detection and Fixes.
What “self-healing” really means
A self-healing test does not magically understand your product. It does one focused job: when a locator fails, it tries to map the failing selector to the most plausible replacement using surrounding context and prior knowledge.
Concretely, a healing layer can use:
- DOM structure and attributes —
id,data-test,data-testid,aria-*, and stable roles. - Text, roles, and labels — for example
role=buttonplus text or accessible name that matches intent. - History from past runs — what worked last time for the same logical step or element key.
- Model-assisted inference — a compact DOM snapshot or candidate list sent to an LLM to propose a locator, often scored for confidence.
In Playwright terms, instead of calling page.click(selector) alone, you route through a wrapper that can catch failures, evaluate alternatives, and—only when confidence is high enough—retry with a new locator while recording that decision.
Example scenario: the original selector is button:has-text("Submit"). The UI changes the copy to “Send” but keeps a primary action in the same form. The healing layer inspects the DOM, finds a similar button (role=button, nearby text, similar layout), proposes a new locator, and if the match score crosses your threshold, retries and logs the change for review.
Why Playwright is a good fit
Playwright already encourages resilient targeting: roles, labels, test ids, and text-based locators are first-class. On top of that you get full page context (page.content(), locators, accessibility tree), plus traces and video for debugging when healing fails or mis-fires—essential in CI where brittle selectors hurt most.
A practical self-healing design does not replace Playwright. It adds a thin layer that:
- Captures failed locators plus compact DOM context.
- Ranks candidate replacements using rules and/or AI.
- Emits structured reports so every auto-change is auditable.
Architecture overview
The diagram below summarizes how baseline tests, failure capture, candidate generation (heuristic, historical, and AI), confidence policy, and reporting connect—with stores, audit trails, and guardrails underneath.
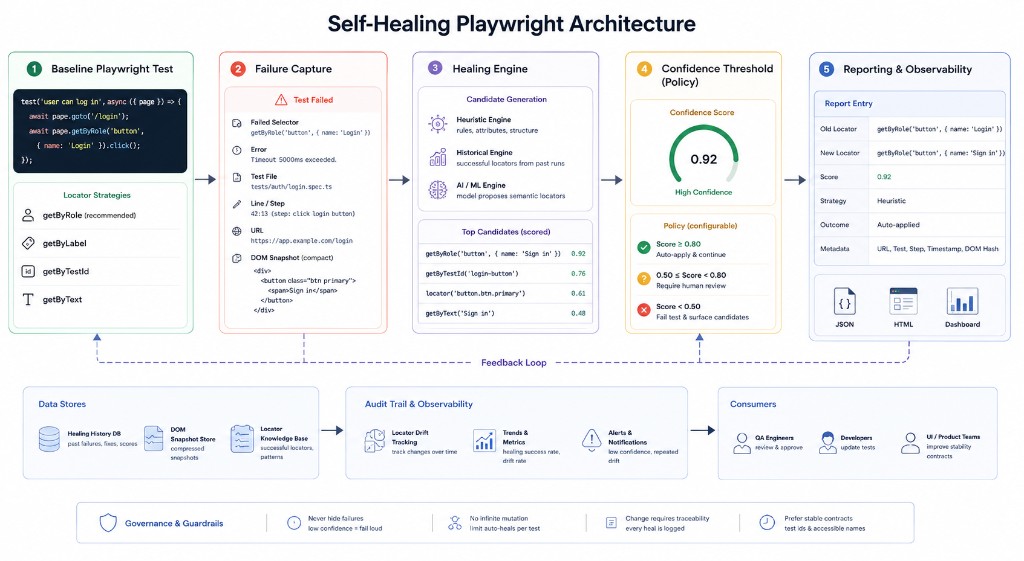
A production-ready self-healing setup usually has five parts:
- Baseline Playwright test — normal test code with your preferred locator strategy (role, label, test id, text).
- Failure capture — failing selector, error, test file, line or step id, URL, and a compact DOM snapshot (not necessarily the whole document).
- Healing engine — module that proposes alternative locators (heuristic, historical, or model-generated) and returns a candidate with a confidence score.
- Confidence threshold — configurable policy: when to auto-apply vs fail loudly and surface candidates for human review.
- Reporting layer — JSON, HTML, or dashboard entries: old locator, new locator, score, strategy, outcome, metadata.
Self-healing must be observable. If selectors mutate silently every run, you lose trust. Teams need an audit trail of locator drift to know when to update tests or push UI teams toward stable contracts (test ids, accessible names).
Setting up the project
Start from a standard Playwright project:
npm init playwright@latestYou get @playwright/test, playwright.config, and a starter suite. To add healing, common approaches are:
- Internal engine — implement healing in your repo (full control, custom rules, on-prem or local models).
- External or community integration — wrap
page/ locators with a library or vendor feature that adds heuristic or model-backed recovery (evaluate licensing, data handling, and whether DOM leaves your boundary).
The following configuration is illustrative of the knobs most designs expose—wire it to your own factory or a chosen package:
// Conceptual — replace createHealingEngine with your implementation or vendor SDK.
import { test } from '@playwright/test';
import { createHealingEngine } from './healing/createHealingEngine';
const healingEngine = createHealingEngine({
apiKey: process.env.HEALING_MODEL_API_KEY,
healingStrategies: ['text', 'role', 'xpath', 'css'],
confidenceThreshold: 0.8,
maxRetries: 3,
debug: true,
reportPath: './healing-reports',
});Typical controls: model or service credentials (if used), strategy list, retry limits, logging, and where reports land.
Baseline Playwright test
Start with a clear, readable test:
import { test, expect } from '@playwright/test';
test('submit form', async ({ page }) => {
await page.goto('https://example.com/contact');
await page.fill('#name', 'John Doe');
await page.fill('#email', 'john.doe@example.com');
await page.click('button:has-text("Submit")');
await expect(page.getByText('Thank you')).toBeVisible();
});This works until the UI evolves. If the button label or markup changes, the locator can fail even when the user flow is still valid—exactly where healing can help if assertions still validate real behavior.
Adding a self-healing wrapper
One pattern is try / catch around the fragile action and delegation to the engine on locator-related failure:
test('submit form with healing', async ({ page }) => {
await page.goto('https://example.com/contact');
await page.fill('#name', 'John Doe');
await page.fill('#email', 'john.doe@example.com');
const primary = 'button:has-text("Submit")';
try {
await page.click(primary);
} catch (error) {
const result = await healingEngine.heal({
originalLocator: primary,
testFile: 'contact.spec.ts',
lineNumber: 8,
// In production, prefer a truncated/sanitized snapshot instead of full HTML.
domSnapshot: await page.content(),
page,
error,
});
if (result.success && result.confidence >= 0.8) {
await page.click(result.newLocator);
} else {
throw error;
}
}
await expect(page.getByText('Thank you')).toBeVisible();
});Healing stays in a dedicated layer; tests stay readable. If healing fails or confidence is low, the test still fails—protecting against false passes.
Mature setups often wrap page in something like a SelfHealingPage so click, fill, and locator share one policy instead of repeating try / catch everywhere.
Heuristic fallbacks first
Not every failure needs a model call. A cost-effective order of operations:
- Try the original locator.
- Try deterministic fallbacks (heuristics).
- Only then call the AI path.
Useful heuristics include:
- Looser text: partial match, case-insensitive, or normalized whitespace.
- Alternate attributes:
data-test,data-testid,data-qa, known id prefixes. - Role plus nearby text (button in the same form with high text similarity).
- A healing store keyed by logical element id (JSON or DB) reusing last-known-good locators.
Heuristics are fast and explainable—use them as the first line of defense before escalating to a model.
AI as a decision layer
Models help when the DOM changes in non-trivial ways: copy changes, layout moves, wrappers from a new component library, or refactored attributes where intent is unchanged (e.g. primary checkout CTA).
A robust model path usually:
- Sends a minimal, high-signal payload: failing selector, URL/title, a short list of visible candidates or a local DOM neighborhood, optional console errors—not entire traces or megabytes of HTML.
- Asks for the best locator for the same intent (“primary submit on this form”).
- Validates the suggestion by performing the action and ensuring downstream assertions still hold before persisting the new locator.
Avoid dumping full traces or raw pages into the prompt: slower, costlier, and noisier with little gain.
Confidence, safety, and guardrails
The main safety valve is a confidence threshold and explicit policy:
- Auto-apply only when confidence meets your bar (for example ≥ 0.8—tune per app).
- Below threshold: fail the test and log the candidate for review instead of guessing.
- Tighten or disable healing on high-risk flows (payments, deletes, admin) where a wrong click is unacceptable.
In QA, a false pass is often worse than a clean failure. Clicking the wrong control while assertions accidentally still pass hides regressions and erodes pipeline trust—overlap with themes in AI Test Hallucinations: Detection and Fixes.
Reporting and observability
Engineers should see exactly what changed and why. Per event, capture:
- Original and new locator, confidence, strategy (heuristic vs model).
- Page URL, title, test name, failure category (text vs attribute vs structural move).
- Timestamp, retries, final outcome.
Export metrics such as heals per suite per week to spot instability or a UI refactor wave. Repeated heals on the same step are a signal to promote the healed locator into the baseline test or to fix the UI contract.
Best practices for self-healing in Playwright
- Prefer resilient locators first — roles, labels, test ids; healing catches edge cases, not sloppy defaults.
- Heal locators, not product behavior — if assertions fail because the flow or validation truly changed, do not mask that with recovery.
- Always enforce confidence — never auto-apply low-confidence guesses on critical paths.
- Log every healing decision — tie into Playwright traces/reports where possible.
- Review and merge healed locators — treat recurring heals as tech debt in tests or UI.
- Use CI policy — optional second run or quarantine job for experiments; do not hide signal.
For selector and wait discipline without AI, Playwright vs Selenium vs Cypress: 2026 Comparison summarizes how Playwright’s auto-waiting and assertions reduce accidental flake.
CI/CD integration
Self-healing is most valuable in CI, where locator noise is expensive.
Typical pipeline behavior:
- On failure, classify locator vs product where possible; healing attempts only the former class.
- If healing succeeds with high confidence, mark the run with a healed flag while keeping artifacts for triage.
- If healing fails or confidence is low, keep the build red with rich diagnostics.
Longer-term policies: break builds if heal rate exceeds a threshold; alert when the same step heals more than N times in a window; trend spikes in healing alongside releases to trigger test refactors.
Real-world example
A checkout test targets button:has-text("Place Order"). Product renames the CTA to “Complete Purchase.” A strict text locator fails even though customers can still buy.
With healing, the engine inspects candidate buttons in the order summary, scores by role, text similarity, and layout, then proposes something like getByRole('button', { name: 'Complete Purchase' }). If the click succeeds and order-confirmation assertions pass, log the event and optionally persist the locator for the next run—while still scheduling a human review of the diff in your healing report.
Common mistakes to avoid
- Over-feeding the model — huge HTML dumps or full traces as prompt filler.
- Over-healing — if tests “never” fail, you may be masking real regressions; recalibrate thresholds and scope.
- Treating healing as a silver bullet — it complements good design and stable
data-testid/ accessible names; it does not replace collaboration with frontend.
Conclusion
AI-powered self-healing can make Playwright suites more resilient when selectors drift, especially in fast-moving products. The implementations that hold up in production combine:
- Strong baseline locators and page structure.
- Deterministic heuristics before model calls.
- Model-based recovery only with validation and confidence gates.
- Explicit reporting and CI policies so signal stays trustworthy.
Used with discipline, self-healing reduces noisy failures and maintenance drag so the team spends more time on real quality risks and less on mechanical selector updates.